Create a Model Serving platform
A crucial phase in the AI lifecycle following model training is to make the models available as a service to be accessed through an API.
KServe offers two deployment modes: Serverless and RawDeployment. During the RHOAI installation, we chose RawDeployment, which is often preferred in cases where simpler, more manual configurations are desired. RawDeployment mode provides full control over Kubernetes resources, enabling detailed customization and configuration of deployment settings without relying on Knative, and therefore, without features like auto-scaling.
In this section you will learn how to set up Red Hat OpenShift AI on Single Node OpenShift to make use of the mentioned RawDeployment model serving to expose both, the stress detection and the time to failure models.
Stress detection model
-
Go back to our Red Hat OpenShift AI Dashboard and make sure you are still inside the
ai-edge-projectproject. -
Navigate to the Models tab.
-
Locate the Single-model serving platform option and choose Select single-model.
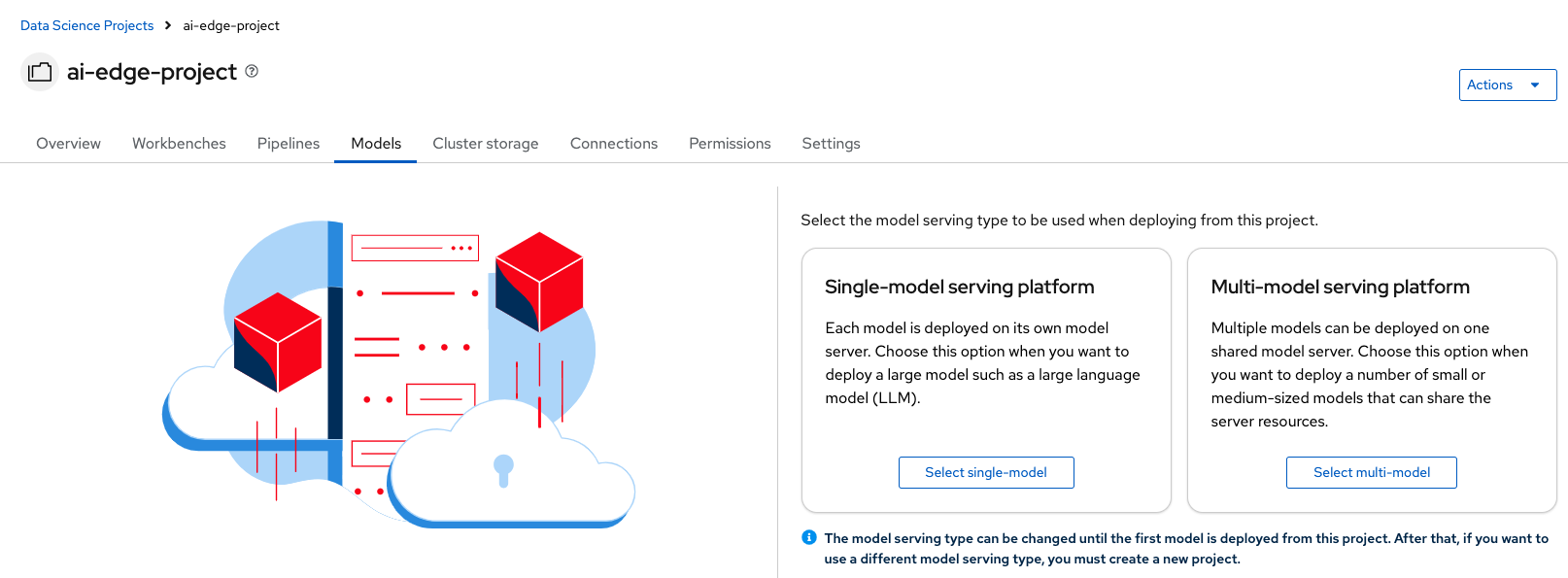
-
This options deploys an associated model server for each model. Click on Deploy model.
-
Complete the following fields in the form:
-
Project: The
ai-edge-projectnamespace should be already selected by default. -
Model deployment name: Type the name for the model server. I will use
Stress Detection. -
Serving runtime: There are different runtimes to choose. I will use the
OpenVINO Model Server; optimized for Intel architectures. -
Model framework: Select the format in which the model was saved. Our model was saved in
openvino_ir - opset13format. -
Model server replicas: Choose the number of pods to serve the model. Just
1should be okay in our case. -
Model server size: Assign resources to the server. Our model is quite simple, so
Smallwill be enough. -
Check the Existing data connection box, if it is not already selected.
-
Connection: Here the
s3-storageDataConnection should appear. Select it. -
Path: Indicate the path to your model location in the S3 bucket. That’s:
models/stress-detection/. We didn’t specify the full path to the model because KServe will automatically pull it from the /1/ subdirectory in the path specified.
-
-
When configured, click on Deploy.
At that moment, new ServingRuntime and InferenceService resources will be created in your node. In the Models tab, your new Model Service should appear. Wait until you see a green checkmark in the Status column. Also, check the Internal endpoint details to show the model inference API where to make requests to.
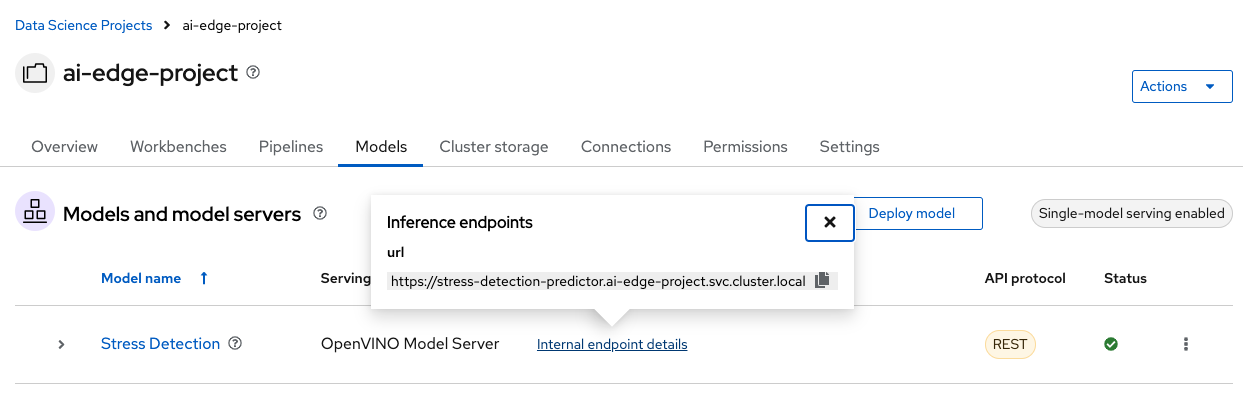
|
The URL shown in the Inference endpoint field for the deployed model is not complete. To send queries to the model, you must add the /v2/models/<model_name>/infer string to the end of the URL. More information can be found in the RHOAIENG-3018 documentation. |
As a result, the model is available as a service and can be accessed using API requests.