Configure a pipeline server
Automation in edge computing is crucial for ensuring reliable and efficient operations in remote environments. Given that many edge deployments are in locations where IT teams are not readily available, it is essential to develop robust and self-sustaining processes that require minimal human intervention. Automated workflows help maintain system stability, optimize performance, and reduce downtime, ensuring that critical applications continue to function without constant manual oversight.
Red Hat OpenShift AI implements Kubeflow Pipelines 2.0. A pipeline is a workflow definition containing steps, inputs, and output artifacts, that are stored in S3-compatible storage. These pipelines enables organizations to standardize and automate machine learning workflows that might include steps such as data extraction, processsing, model training and validation.
In order to be able to run pipelines in RHOAI, first a pipelines server is needed. The pipeline server instance creates the necessary pods to manage and execute data science pipelines. Let’s review the process to creatae the server:
-
Navigate back to the Red Hat OpenShift AI Dashboard.
-
In your
ai-edge-projectproject dashboard, navigate to the Pipelines tab. -
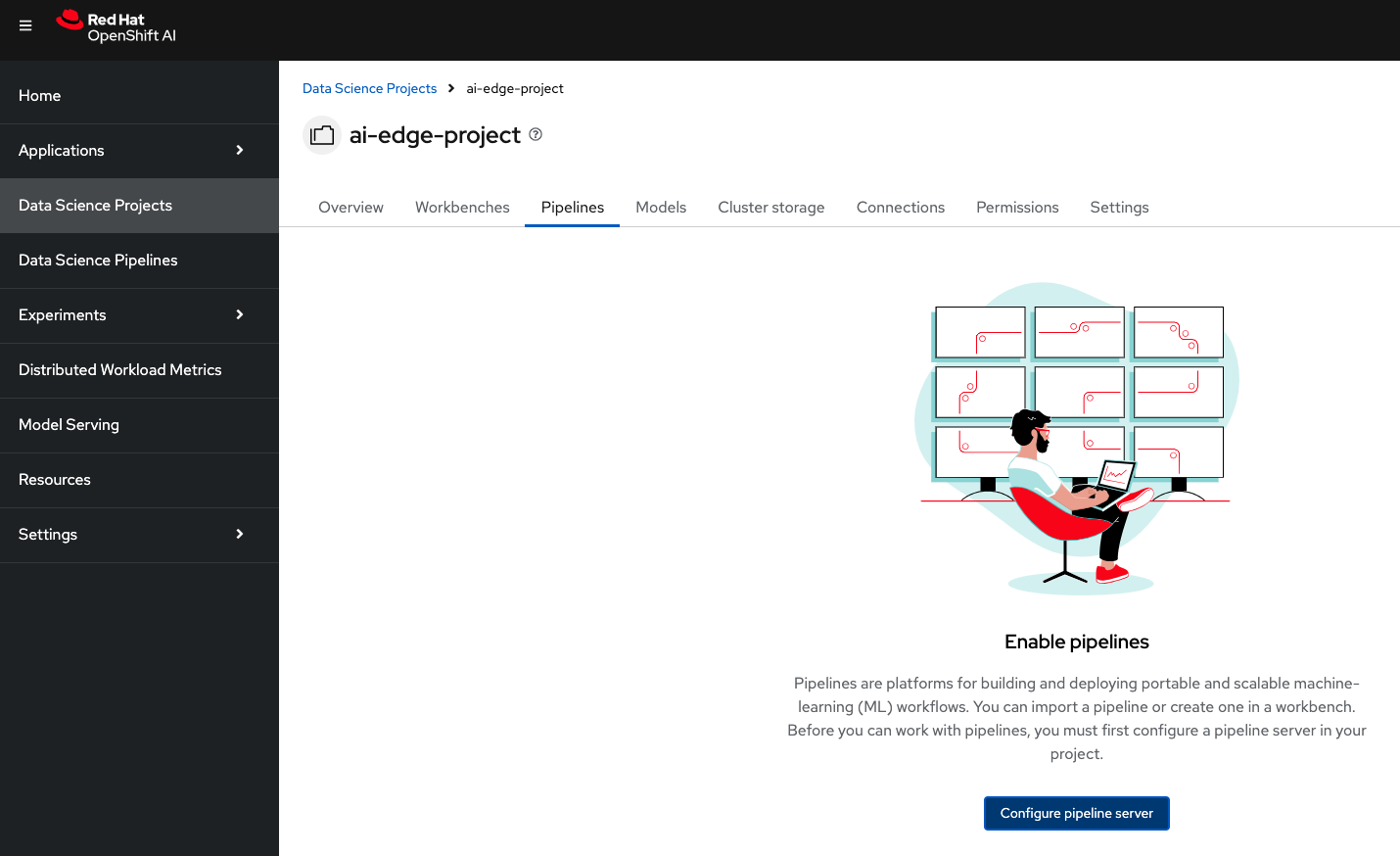
Before starting using pipelines, we need to create the server. Click on Configure pipeline server.
-
Here we need to create a new Object storage connection that uses our pipelines bucket. Complete the fields with your s3 data:
-
Access key: Type the MinIO username. In this case
minio. -
Secret key: The password for the previous user will be
minio123. -
Endpoint: Specify the MinIO API endpoint:
http://minio-service.minio.svc.cluster.local:9000. -
Region: The default value is
us-east-1. -
Bucket: Indicate the
pipelinesbucket name.
-
-
When filled, scroll down and press Configure pipeline server.
When we create the server, a new DataSciencePipelineApplication custom resource is created in your OpenShift and provides an API endpoint and a database for storing metadata. Wait until the process is complete. Take into account that it might take a few minutes to finish. Once ready, the Import pipeline option should appear: