Create a Model Serving platform
It’s time to repeat the same steps for the Time to Failure AI model. The steps will be quite similar, but make sure you specify the right path to our second model.
Time to Failure model
-
Ensure you are in the Models tab inside our
ai-edge-projectproject. -
Click on Deploy model.
-
Complete again the following fields in the form:
-
Project: The
ai-edge-projectnamespace should be already selected by default. -
Model deployment name: Name for the
Time to Failuremodel server. -
Serving runtime: Choose
OpenVINO Model Serverruntime. -
Model framework: Our model was saved in
openvino_ir - opset13format. -
Model server replicas: Keep
1for the number of pods. -
Model server size: Assign
Smallto the server size. -
Check the Existing data connection box.
-
Connection: Select again the
s3-storageDataConnection. -
Path: Our Time to Failure model was saved in
models/time-to-failure/.
-
-
Finally, click on Deploy.
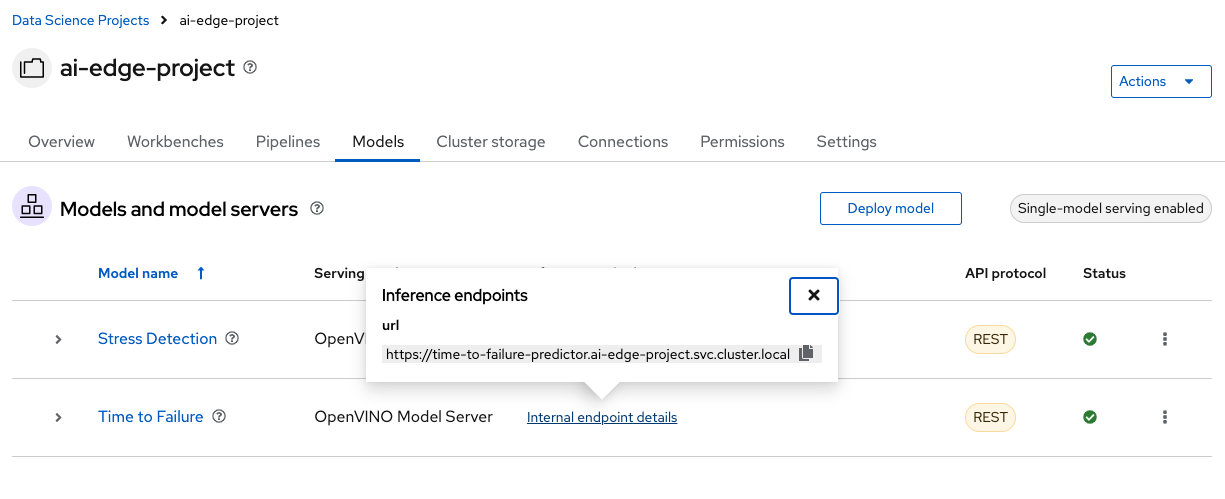
Wait until you see a green checkmark in the Status column. Then, the Internal endpoint details will show the model inference API for our second AI model.